Técnicas de Modelação de Dados
Iniciado a 02/10/2024 - Completo a 21/10/2024
As bases de dados relacionais organizam a informação em tabelas que contêm registos (linhas) e campos (colunas).
Vamos detalhar esses conceitos e os relacionados a índices e chaves:
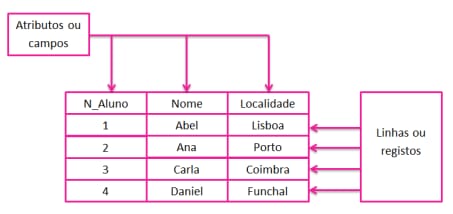
Uma tabela em uma base de dados relacional é uma estrutura que armazena dados de forma organizada. Ela é composta por linhas (ou registros) e colunas (ou campos).
Cada linha representa um registo único, enquanto cada coluna contém um tipo específico de dado referente a esse registo.
Linhas (Registos): Representam posições de dados, ou seja, cada linha contém os dados de um único item ou entidade.
Por exemplo, numa tabela de clientes, cada linha poderia representar um cliente específico.
Atributos (Campos): Definem os tipos de dados que podem ser armazenados na tabela. Cada coluna tem um nome e um tipo de dado (números, texto, datas, etc.).
Continuando o exemplo da tabela de clientes, as colunas poderiam ser "N_Alunos", "Nome", "Localidade" etc.
Um índice é uma estrutura que melhora a eficiência de operações de busca e acesso aos dados.
Ele funciona de forma semelhante ao índice de um livro, permitindo que o sistema localize rapidamente os registos em uma tabela com base em valores de uma ou mais colunas.
Chaves de indexação simples: São índices criados sobre uma única coluna. Por exemplo, um índice baseado na coluna "ID" de uma tabela de clientes.
Por exemplo, um índice criado com base nas colunas "Nome" e "Telefone" de uma tabela pode acelerar pesquisas onde ambas as colunas são usadas.
Os índices ajudam a melhorar o desempenho das operações de consulta,
Mas também podem consumir mais espaço em disco e aumentar o tempo necessário para inserir e atualizar dados.
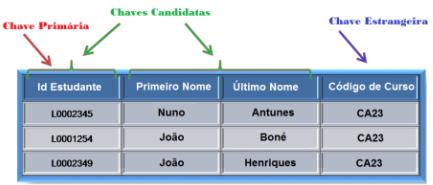
Chave Candidata: Uma chave candidata é qualquer coluna ou combinação de colunas que pode ser usada de maneira única para identificar um registo na tabela.
Uma tabela pode ter várias chaves candidatas, mas apenas uma será escolhida como a chave primária.
Exemplo: Em uma tabela de clientes, tanto o "ID" como o "Número do CC" podem ser chaves candidatas, pois ambos podem identificar exclusivamente um cliente.
Chave Primária (Primary Key) A chave primária é a chave candidata escolhida para identificar exclusivamente os registos na tabela.
Cada tabela deve ter apenas uma chave primária, e os valores dessa chave não podem ser nulos ou duplicados.
Exemplo: Na tabela de clientes, o campo "ID" pode ser escolhido como chave primária. Assim, cada cliente terá um número de "ID" único, que o identifica.
Chave Externa (Estrangeira) Uma chave externa é uma coluna (ou um conjunto de colunas) que estabelece um vínculo entre duas tabelas.
Ela faz referência à chave primária de outra tabela, criando uma relação entre os dados.
Isso é fundamental para manter a integridade referencial em bases de dados relacionais.
Exemplo: Se houver uma tabela de "Pedidos" e uma tabela de "Clientes", a tabela "Pedidos" pode ter uma coluna "Cliente_ID"
que seja uma chave externa que aponta para a chave primária "ID" na tabela de "Clientes".
Isso significa que cada pedido está relacionado a um cliente específico.
Esses conceitos são essenciais para a modelagem, integridade e otimização do acesso aos dados em bases de dados relacionais.
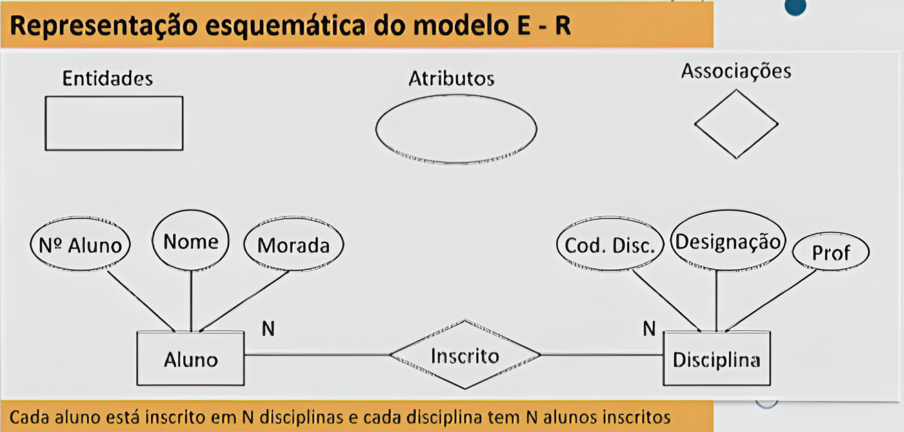
Relação 1-1 (Um para Um): Cada registo numa tabela corresponde a um único registo numa outra tabela.
Exemplo: Uma tabela de Pessoas e uma tabela de Documentos.
Relação 1-N (Um para Muitos): Um registo numa tabela pode estar associado a múltiplos registos numa outra tabela.
Exemplo: Uma tabela de Autores e uma tabela de Livros.
Relação N-N (Muitos para Muitos): Registos numa tabela podem estar associados a múltiplos registos numa outra tabela e vice-versa.
Exemplo: Uma tabela de Alunos e uma tabela de Disciplinas, com uma tabela intermédia Inscrições para mapear a relação.
A integridade de dados é a garantia de que as informações de uma organização são precisas, completas e consistentes ao longo de seu ciclo de vida.
É crucial para a tomada de decisões e proteção contra violações de dados.
Para manter a integridade, as organizações utilizam processos como verificação de erros, validações e medidas de segurança, como criptografia e backups.
A integridade dos dados envolve um esforço coletivo de tecnologia, políticas e pessoas, assegurando que os dados permaneçam um ativo confiável.
Ela se opõe à decomposição dos dados e visa evitar mudanças não intencionais nas informações, não devendo ser confundida com segurança de dados.
A normalização é o processo de organização de dados numa base de dados.
Inclui a criação de tabelas e o estabelecimento de relações entre essas tabelas de acordo
com regras concebidas para proteger os dados e tornar a base de dados mais flexível, eliminando redundância e dependência inconsistente.
Redução de Redundância: A normalização minimiza a duplicação de dados, economizando espaço de armazenamento.
Integridade dos Dados: Com menos duplicações, a integridade referencial é melhor mantida, reduzindo a probabilidade de inconsistências.
1ª Forma normal:Elimine grupos repetidos em tabelas individuais.
• Crie uma tabela separada para cada conjunto de dados relacionados.
• Identifique cada conjunto de dados relacionados com uma chave primária.
2ª Forma normal: Crie tabelas separadas para conjuntos de valores que se aplicam a registos diversos.
• Relacione estas tabelas com uma chave externa.
3ª Formal normal: Elimine campos que não dependem da chave.
A desnormalização é usada para otimizar a performance de consultas ao reduzir junções e simplificar os acesso a dados